
英伟达Tesla A100 40G/80G训练推理运算加速显卡
适用各种工作负载的出色计算平台NVIDIA ® A100 Tensor Core GPU 可针对 AI、数据分析和高性能计算 (HPC) 应用,在各个规模下实现出色加速,有效助力全球高性能弹性数据中心。
- 显存:40GB/80GB
- 显存带宽:1555GB/s
- CUDA核数:6912;
- 应用:科学计算、深度学习/训练+推理等
- 参考价格:69000元
- 采购报价联系:13048086411
产品详情
Tesla A100计算卡采用了7nm工艺的GA100 GPU,这款GPU拥有6912 CUDA核心和432张量核心。GPU封装尺寸为826mm2,集成了540亿个晶体管。
该卡支持第三代NVLINK,与服务器的双向带宽为4.8 TB/s, GPU到GPU的互连带宽为600 GB/s。Tesla A100拥有40GB的HBM2显存,显存位宽为5120-bit,TDP为400W。
A100 PCIe的TDP为250W,而之前发布的SXM版本TDP为400W。对此,NVIDIA表示,尽管PCIe型号的TDP较低,但两种型号的峰值功率是相同的,只是在持续负载下,PCIe版的性能会比基于SXM的型号低10%到50%。


GPU加速计算
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和高性能计算 (HPC),在各种规模上实现出色的加速,应对极其严峻的计算挑战。作为 NVIDIA 数据中心平台的引擎,A100 可以高效扩展,系统中可以集成数千个 A100 GPU,也可以利用 NVIDIA 多实例 GPU (MIG) 技术将每个 A100 划分割为七个独立的 GPU 实例,以加速各种规模的工作负载。第三代 Tensor Core 技术为各种工作负载的更多精度水平提供加速支持,缩短获取洞见以及产品上市时间。
功能强大的端到端 AI 和 HPC 数据中心平台
A100 是完整的 NVIDIA 数据中心解决方案堆栈的一部分,该解决方案堆栈包括来自 NGC (NVIDIA GPU Cloud) 的硬件、网络、软件、库以及优化的 AI 模型和应用程序构建模块。它为数据中心提供了强大的端到端 AI 和 HPC 平台,使研究人员能够大规模地交付真实的结果,并将解决方案大规模部署到生产环境中。
AI 数据中心的基本组成部分
深度学习推理
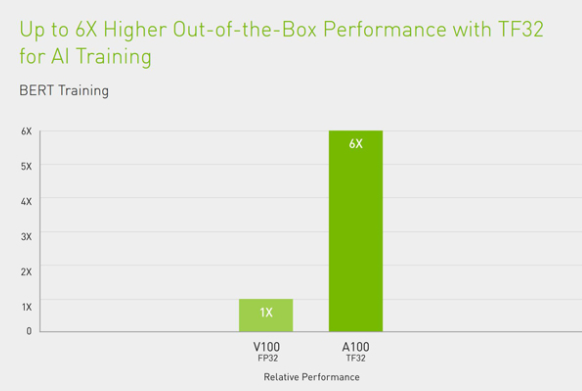
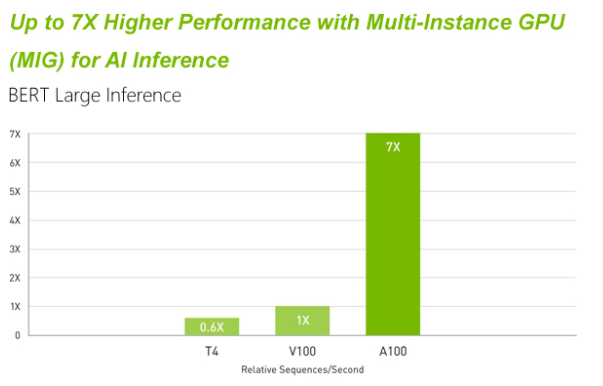
A100 引入了突破性的新功能优化推理工作负载。它通过全系列精度(从 FP32、FP16、INT8 一直到 INT4)加速,实现了强大的多元化用途。MIG 技术支持多个网络同时在单个 A100 GPU 运行,从而优化计算资源的利用率。在 A100 其他推理性能提升的基础上,结构化稀疏支持将性能再提升两倍。
NVIDIA 提供市场领先的推理性能,在第一项专门针对推理性能的行业级基准测试 MLPerf Inference 0.5中全面制胜的结果充分证明了这一点。A100 则再将性能提升 10 倍,在这样的领先基础上进一步取得了发展。
高性能计算
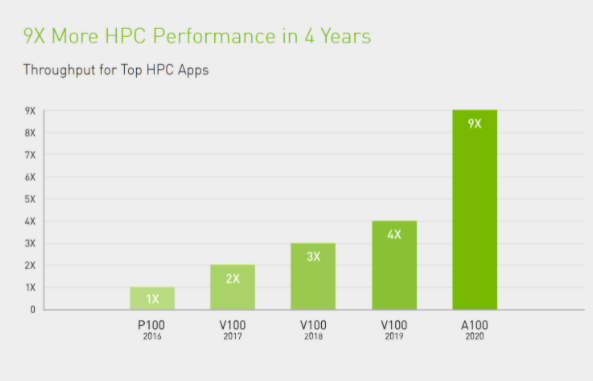
为了点燃下一代新发现的火花,科学家们希望通过模拟更好地理解复杂分子结构以支持药物发现,通过模拟物理效果寻找潜在的新能源,通过模拟大气数据更好地预测极端天气状况并为其做准备。
A100 引入了双精度 Tensor Cores, 继用于 HPC 的 GPU 双精度计算技术推出至今,这是非常重要的里程碑。利用 A100,原本在 NVIDIA V100 Tensor Core GPU 上需要 10 小时的双精度模拟作业如今只要 4 小时就能完成。HPC 应用还可以利用 A100 的 Tensor Core,将单精度矩阵乘法运算的吞吐量提高 10 倍之多。
数据分析
客户需要能够分析和可视化庞大的数据集,并将其转化为宝贵洞见。但是,由于这些数据集分散在多台服务器上,横向扩展解决方案往往会陷入困境。
搭载 A100 的加速服务器可以提供必要的计算能力,并利用第三代 NVLink 和 NVSwitch 1.6TB/s 的显存带宽和可扩展性,妥善应对这些庞大的工作负载。结合 Mellanox InfiniBand、Magnum IO SDK、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS NVIDIA 数据中心平台能够以出色的性能和效率加速这些大规模工作负载。
企业级利用率
A100 的 多实例 GPU (MIG) 功能使 GPU 加速的基础架构利用率大幅提升,达到前所未有的水平。MIG 支持将 A100 GPU 安全分割到多达七个独立实例中,这些 A100 GPU 实例可供多名用户使用,以加速应用和开发项目。此外,数据中心管理员可以利用基于虚拟化技术带来的管理、监控和操作方面的优势,发挥 NVIDIA 虚拟计算服务器 ( vComputeServer) 的动态迁移和多租户功能。A100 的 MIG 功能可以使基础架构管理员对其 GPU 加速的基础架构作标准化处理,同时以更精确的粒度提供 GPU 资源,从而为开发者提供正确的加速计算量,并确保其所有 GPU 资源得到充分利用。
将深度学习的强大功能应用于数据
云计算通过实现数据中心的大众化和彻底改变企业的运作方式,引发了行业变革。如今,您最重要的资产位于您的首选提供商提供的云服务中。然而,要从数据中充分获取见解,您需要合适的高性能计算解决方案。
GPU 加速云容器
NVIDIA GPU 云 (NGC) 可以通过 GPU 加速的容器为人工智能科学家和研究人员赋予强大能力。NGC 提供 TensorFlow、PyTorch、MXNet 等容器化深度学习框架,它们都经过 NVIDIA 的调试、测试和验证,可以在参与计划的云服务提供商的最新 NVIDIA GPU 上运行。NGC 还包含用于 HPC 应用的第三方管理容器以及用于 HPC 可视化的 NVIDIA 容器。
适用于边缘 AI 的解决方案
打造更高效、更智能的世界
AI 在边缘蓬勃发展。AI 和云原生应用程序、物联网及其数十亿的传感器以及 5G 网络现已使得在边缘大规模部署 AI 成为可能。但它需要一个可扩展的加速平台,能够实时推动决策,并让各个行业都能为行动点(商店、制造工厂、医院和智慧城市)提供自动化智能。这将人、企业和加速服务融合在一起,从而使世界变得“更小”、更紧密。
英伟达A100显卡详细规格参数
| A100 40GB PCIE | A100 80GB PCIE | A100 40GB SXM | A100 80GB SXM | |
| FP64 | 9.7 TFLOPS | |||
| FP64 Tensor Core | 19.5 TFLOPS | |||
| FP32 | 19.5 TFLOPS | |||
| Tensor Float 32 (TF32) | 156 TFLOPS | 312 TFLOPS* | |||
| BFLOAT16 Tensor Core | 312 TFLOPS | 624 TFLOPS* | |||
| FP16 Tensor Core | 312 TFLOPS | 624 TFLOPS* | |||
| INT8 Tensor Core | 624 TOPS | 1248 TOPS* | |||
| GPU 显存 | 40GB HBM2 | 80GB HBM2e | 40GB HBM2 | 80GB HBM2e |
| GPU 显存带宽 | 1,555GB/s | 1,935GB/s | 1,555GB/s | 2,039GB/s |
| 最大热设计功耗 (TDP) | 250W | 300W | 400W | 400W |
| 多实例 GPU | 最大为 7 MIG @ 5GB | 最大为 7 MIG @ 10GB | 最大为 7 MIG @ 5GB | 最大为 7 MIG @ 10GB |
| 外形规格 | PCIe | SXM | ||
| 互联 |
NVIDIA® NVLink® 桥接器(可桥接 2 个 GPU): 600GB/s ** PCIe 4.0:64GB/s |
NVLink: 600GB/s PCIe Gen4: 64GB/s | ||









