网盘索引时,发现数据库报错网页加载不进去. 于是去服务器后台看了下服务器的运行情况. 发现服务器的储存空间爆满了一点空间都没有,数据库等等的运行不下去都自动掉了,可能是由于长期的缓存和日志文件吧空间挤满了吧. 所以我去查看了宝塔的日志文件和数据库的二进制文件. 查看下来发现并没有问题.采取进一步的排查工作了. 当时的想是级一级的查看每个目录都占用了多少空间.

分析:内存持续飙升,应该是有大量内存一直没有释放,考虑僵尸对象,僵尸进程,最简单的就是重启服务器,但是就无法找到罪魁祸首了。
验证:top命令查看活跃进程的资源使用情况。(top命令是linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用实况,类似于windows的任务管理器)
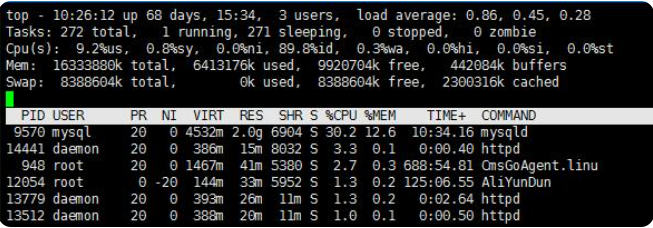
显然活跃进程占用的内存并不多,造成内存爆满的另有它因。
ps -aux 查看当前系统的进程状态。看到有大量的postdrop和sendmail
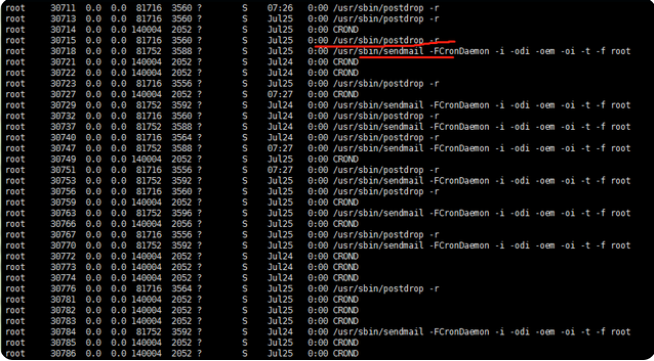
顺藤摸瓜,就找到了sendmail和postdrop上,通过重启postfix,内存使用立马断崖式下跌。问题暂时得到解决。如下图所示
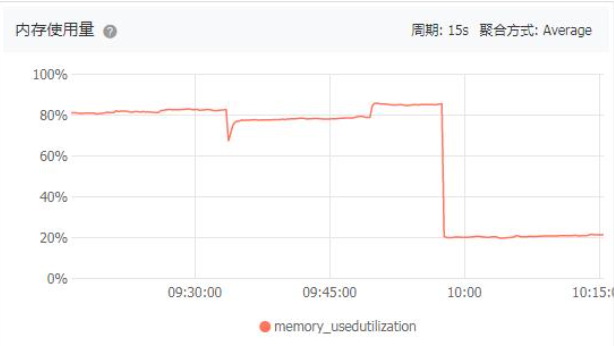
终极解决方案:
postdrop是由sendmail启动的,而sendmail又是由crond启动的。所以根在crond服务上。
问题成因:crond在执行脚本时会将脚本输出信息以邮件的形式发送给系统用户,所以必然要调用sendmail,而sendmail又会调用postdrop发送邮件,但是如果系统的postfix服务没有正常运行,那么邮件就会发送不成功,造成sendmail、postdrop、crond进程就无法正常退出,形成大量的僵尸进程
解决办法:先把僵尸进程都干掉ps -ef | egrep “sendmail|postdrop” | grep -v grep |xargs kill,让内存降下来,其实我一开始就是将postfix服务重启了一下,问题就解决了,观察了一段时间,僵尸进程并没有再次出现。
为防以后postfix挂了再出现类似问题,可以进行如下配置,将crond的邮件通知关闭:
将/etc/crontab和/etc/cron.d/0hourly里的MAILTO=root修改为MAILTO=””
crontab -e第一行增加一段MAILTO=””











